I'm doing a presentation on non-relational databases at DDD Melbourne this weekend where I am going to demonstrate a map-reduce example with MongoDB and server side Javascript. I've been interested in both independently recently and it's been fun getting them to working together with some Javascript TDD to boot.
I needed a good example to demonstrate map-reduce and decided finding word occurrences across a series of documented seemed a simple enough scenario that is suited to being solved by a map-reduce query.
Below is an example of how we might solve this in plain C#
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
class wordCounts {
static void Main(string[] args) {
// Setup some data
List<string> lines = new List<string>()
{
"Peter Piper picked a peck of pickled peppers",
"A peck of pickled peppers Peter Piper picked",
"If Peter Piper picked a peck of pickled peppers",
"Where's the peck of pickled peppers Peter Piper picked?"
};
// select all words, group, count
var wordCounts = lines.SelectMany(m => m.Split())
.GroupBy(m => m.ToLower())
.Select(m => new KeyValuePair<string,int>(m.Key, m.Count()));
// Print out the results
foreach (var wordCount in wordCounts)
{
Console.WriteLine(string.Format("{0} {1}", wordCount.Value, wordCount.Key));
}
}
}
This prints each different word in all the lines and the number of the times it occurs. The collection of strings is isomorphic to a collection of documents in the MongoDB for this example.
The SelectMany flattens lists of words from each line to a single list of words and the Group provides keys for each word, this is very similar to what the map function in the map-reduce query does.
The Select function is similar to the reduce function, but as we will see some additional considerations need to be made to allow it to be distributed.
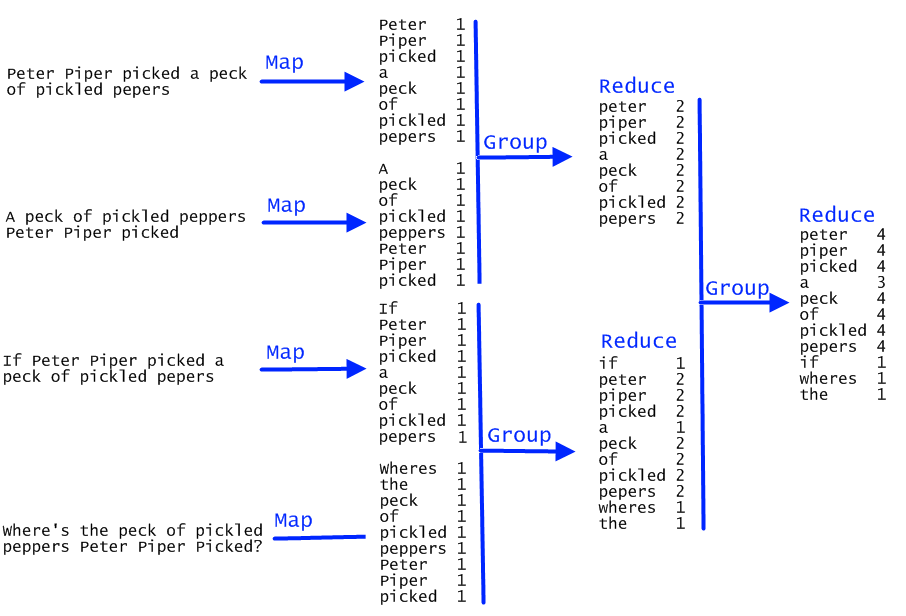
I saw a good diagram ayande published on his blog but I didn't understand why he had multiple instance of the same document being mapped.
I created my own low key diagram to help demonstrate how a functional map- reduce could be distributed. The diagram shows the initial items can be split in half and reduced completely independently. This is interesting as it means our query can be distributed, but it also means we have to handle reducing a little differently.
It's also worth noting that this example shows a balanced tree, but it could be unbalanced and even introduce some redundancy.
MongoDB allows clients to send JavaScript map and reduce functions that will get eval'd and run on the server. Here is the map function.
function wordMap() {
// try find words in document text
var words = this.text.match(/\w+/g);
if (words === null) {
return;
}
// loop every word in the document
for (var i = 0; i < words.length; i++) {
// emit every word, with count of one
emit(words[i], { count : 1 });
}
}
The misunderstood Javascript "this" will be the context from which the function is called. Mongo will call function each document in the collection we are querying, and we can call it from a test context. Unlike the SelectMany the map function doesn't return a list, instead it calls an emit function which it expects to be defined.
We can write unit tests for this function by calling the function from a test mock context, calling a mock emit function (using Javascript as our mocking framework, wow).
eval(loadFile("src/js/wordMap.js"));
var emit;
var results;
var context;
testCases(test,
function setUp() {
emit = function (key, value) {
results.push({ key : key, value : value });
};
context = { text : "", map : wordMap };
results = [];
},
function empty_string_emits_nothing() {
context.text = "";
context.map();
assert.that(results.length, eq(0));
},
function single_word_emits_single_word() {
context.text = "findme";
context.map();
assert.that(results.length, eq(1));
assert.that(results[0].key, eq("findme"));
assert.that(results[0].value.count, eq(1));
},
function two_different_words_emits_twice() {
context.text = "for bar";
context.map();
assert.that(results.length, eq(2));
},
function two_same_words_emits_twice() {
context.text = "test test";
context.map();
assert.that(results.length, eq(2));
},
function tearDown() {
}
);
The reduce function must reduce a list of a chosen type to a single value of that same type; it must be transitive so it doesn't matter how the mapped items are grouped.
function wordReduce(key, values) {
var total = 0;
for (var i = 0; i < values.length; i++) {
total += values[i].count;
}
return { count : total };
}
Similarly we can test this method does exactly what we expect it to.
eval(loadFile("src/js/wordReduce.js"));
testCases(test,
function reduce_one_items_returns_count_of_one() {
var result = wordReduce("test", [{ count : 1 }]);
assert.that(result.count, eq(1));
},
function reduce_multiple_items_returns_item_count() {
var result = wordReduce("test", [{ count : 1 }, { count : 1 }, { count : 1 }]);
assert.that(result.count, eq(3));
},
function reduce_sums_counts() {
var result = wordReduce("test", [{ count : 2 }, { count : 3 }]);
assert.that(result.count, eq(5));
},
function reduce_is_transitive() {
var result = wordReduce("test", [{ count : 1 }].concat(
wordReduce("test", [{ count : 1 }, { count : 1 }]
));
assert.that(result.count, eq(3));
}
);
I'm using Rhino to run the Javascript so I used RhinoUnit as a test runner as it also uses the JVM and runs as an ANT scriptdef task, the setup was pretty painless. Here are the relevant ANT script sections
<scriptdef name="rhinounit"
src="lib/rhinoUnitAnt.js"
language="javascript">
<attribute name="options"/>
<attribute name="ignoredglobalvars"/>
<attribute name="haltOnFirstFailure"/>
<attribute name="rhinoUnitUtilPath"/>
<element name="fileset" type="fileset"/>
</scriptdef>
<target name="javascript-tests">
<rhinounit options="{verbose:true, stackTrace:true}"
haltOnFirstFailure="false"
rhinoUnitUtilPath="lib/rhinoUnitUtil.js">
<fileset dir="test">
<include name="*.js"/>
</fileset>
</rhinounit>
</target>
The word count example recreated in Mongo using a Python client and passing the map/reduce functions to the server.
from pymongo import Connection;
from pymongo.code import Code;
# open connection and connect to 'ddd' database
connection = Connection()
db = connection.ddd
# remove any existing data
db.drop_collection("messages")
# insert some data
lines = open("data/peter_piper.txt").readlines();
for line in lines:
db.messages.insert( { "text" : line } )
# load map and reduce functions
map = Code(open("src/js/wordMap.js","r").read())
reduce = Code(open("src/js/wordReduce.js","r").read())
# run the map-reduce query
result = db.messages.map_reduce(map, reduce)
# print the results
for doc in result.find():
print doc["value"]["count"],doc["_id"]
And it worked! I'd like to run the query on a larger result-set, but there isn't much point on this tiny low-spec'd netbook.
Comments
Thanks you very much for this clean tutorial.
I get borrowed from you the diagram to illustrate a presentation I am doing on Map-Reduce over MongoDB.
Regards and good work!